Friendli Engine
About Friendli Engine
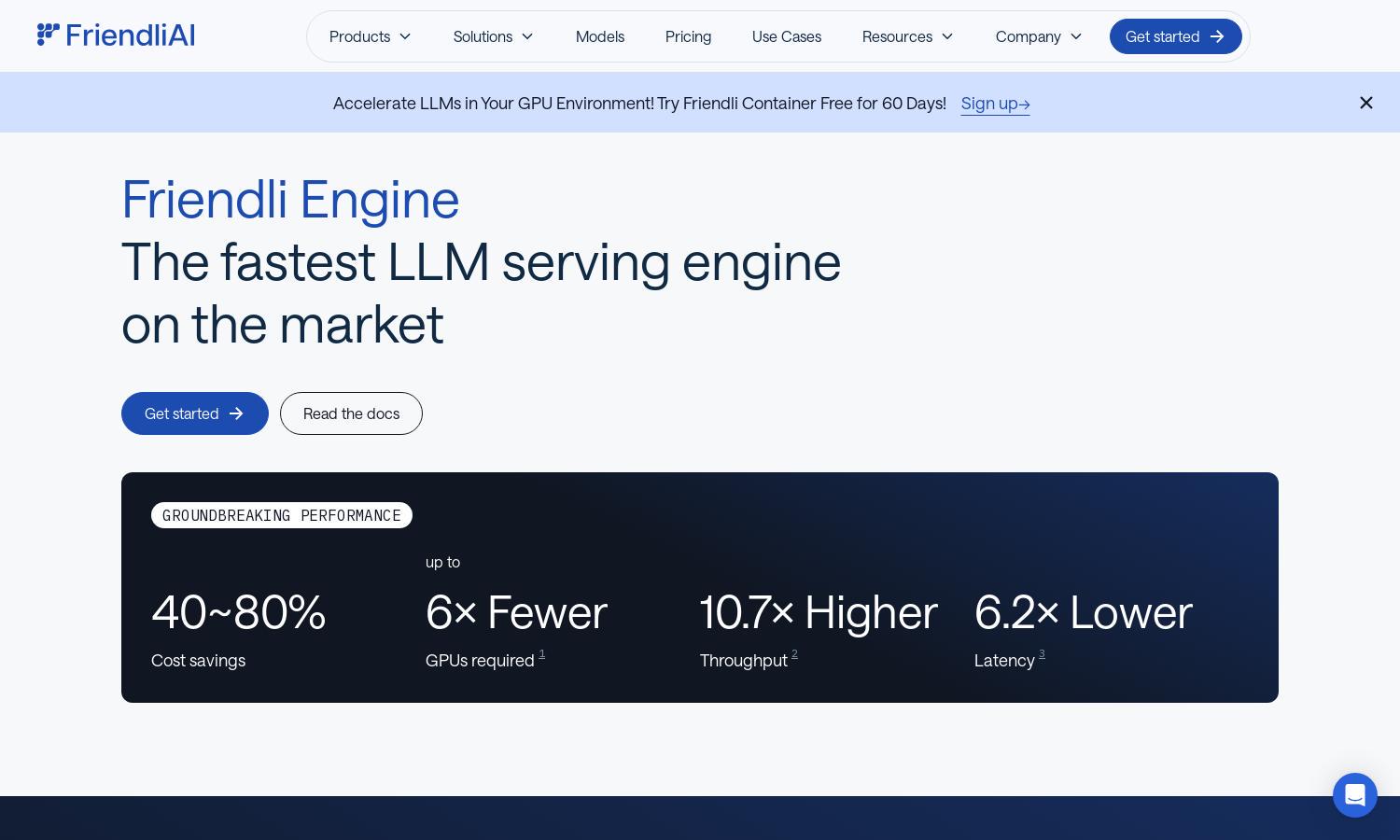
Friendli Engine is designed to revolutionize LLM serving, providing outstanding performance and cost savings. It leverages advanced technologies like iteration batching and speculative decoding to deliver faster results with fewer resources. Targeted at developers and businesses, it makes generative AI accessible and efficient for all.
Friendli Engine offers flexible pricing plans tailored to various user needs. From free trials to premium subscriptions, each tier is designed to deliver exceptional value while maximizing performance benefits. Users upgrading can access expanded features, ensuring they get the most from their generative AI experience.
Friendli Engine features an intuitive interface that simplifies user interactions. Its clean layout promotes easy navigation, allowing users to quickly access and deploy LLMs. With user-friendly elements and optimized design, Friendli Engine ensures a smooth and enjoyable experience for both newcomers and seasoned experts alike.
How Friendli Engine works
Users begin by signing up for Friendli Engine, where they can explore its powerful features. After onboarding, they can deploy generative AI models effortlessly using the dedicated endpoints or container options. The platform also allows API access for further integration, ensuring a seamless experience tailored to diverse user requirements.
Key Features for Friendli Engine
Iteration Batching
Iteration Batching is a unique feature of Friendli Engine, enhancing LLM inference throughput significantly. This technology allows for the efficient handling of concurrent requests, achieving up to tens of times higher throughput. Friendli Engine capitalizes on this to deliver faster results for all generative AI tasks.
Speculative Decoding
Speculative Decoding in Friendli Engine accelerates the inference process by predicting future tokens while generating the current one. This innovative approach ensures high accuracy while reducing the time taken for inferring, making it an essential feature for users looking to optimize their AI implementations.
Multi-LoRA Support
Friendli Engine supports Multi-LoRA, allowing users to work with multiple LoRA models concurrently on fewer GPUs. This feature enhances the customization and scalability of generative AI applications, making it easier and more efficient for users to fine-tune their models without needing extensive resources.
You may also like: