SpeechEasy
About SpeechEasy
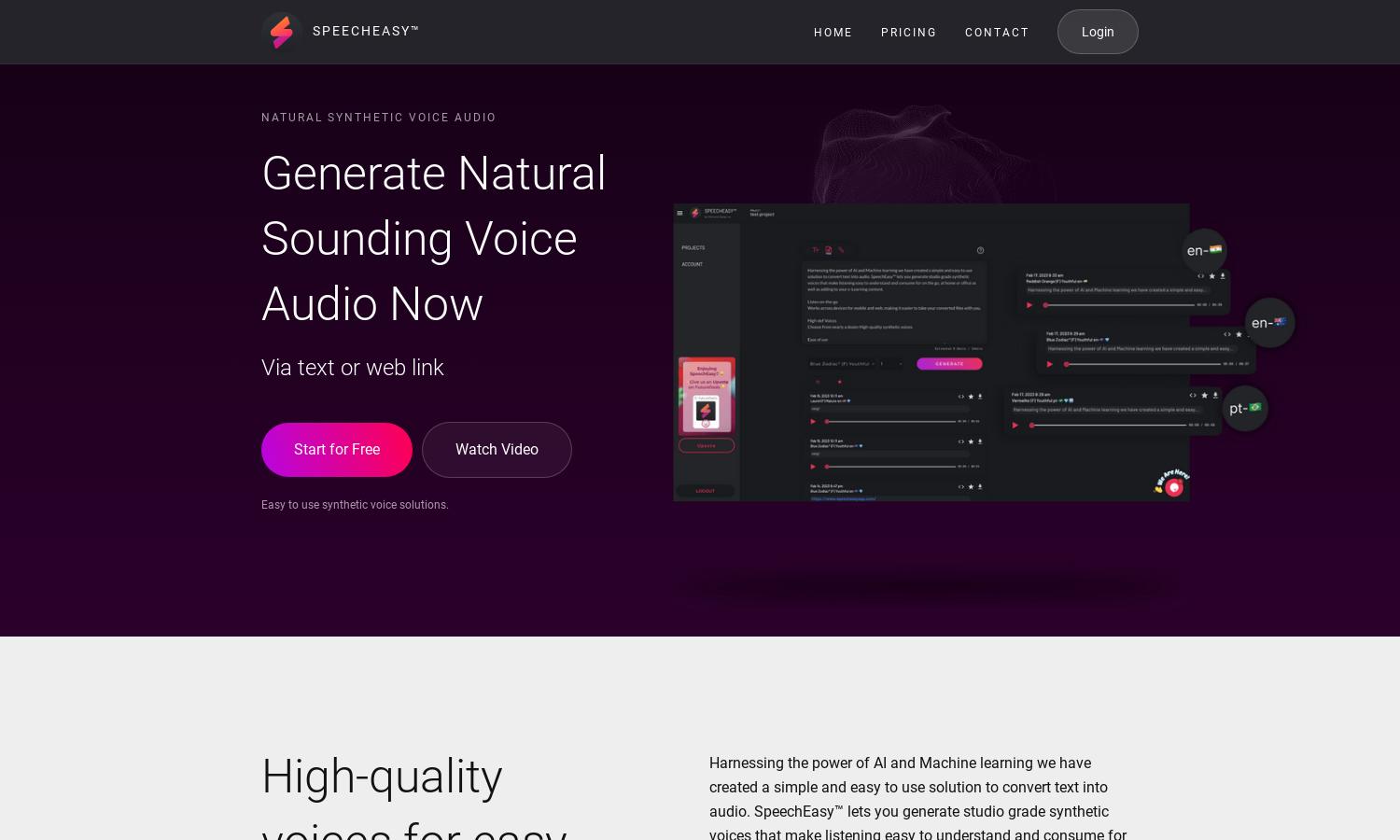
SpeechEasy is a pioneering text-to-speech platform designed for users who seek high-quality audio solutions. It harnesses advanced AI technology to provide natural, studio-grade synthetic voices that are easy to understand, making it perfect for e-learning, podcasts, and entertainment.
SpeechEasy offers a free starter plan, giving users access to all voices and features. Content creators can upgrade for enhanced tools, while marketers and enterprise users can explore tailored pricing. The platform ensures value at every level, optimizing the user experience.
The user-friendly interface of SpeechEasy simplifies the text-to-speech process. Its intuitive layout allows seamless navigation through features and options, ensuring users can generate high-quality audio effortlessly. The design focuses on maximizing productivity without unnecessary distractions, enhancing overall experience.
How SpeechEasy works
Users begin with a simple onboarding process, creating an account on SpeechEasy. After logging in, they can easily input text or web links to generate audio. The platform's straightforward interface allows users to customize voice options, listen to generated audio, and download files across devices.
Key Features for SpeechEasy
High-Quality Synthetic Voices
SpeechEasy delivers nearly a dozen high-quality synthetic voices, allowing users to select an option that fits their needs. This feature ensures a natural listening experience, making it ideal for various applications, from e-learning to content creation.
Cross-Platform Support
SpeechEasy offers exceptional cross-platform support, allowing users to access and play audio files seamlessly on both mobile and web devices. This feature enhances convenience, making it easy to consume generated content anywhere, anytime.
Privacy and Security
SpeechEasy prioritizes user privacy and security, implementing a minimal data collection approach to safeguard personal information. Users can trust that their data is protected while enjoying the benefits of the platform's powerful text-to-speech capabilities.
You may also like: