dstack
About dstack
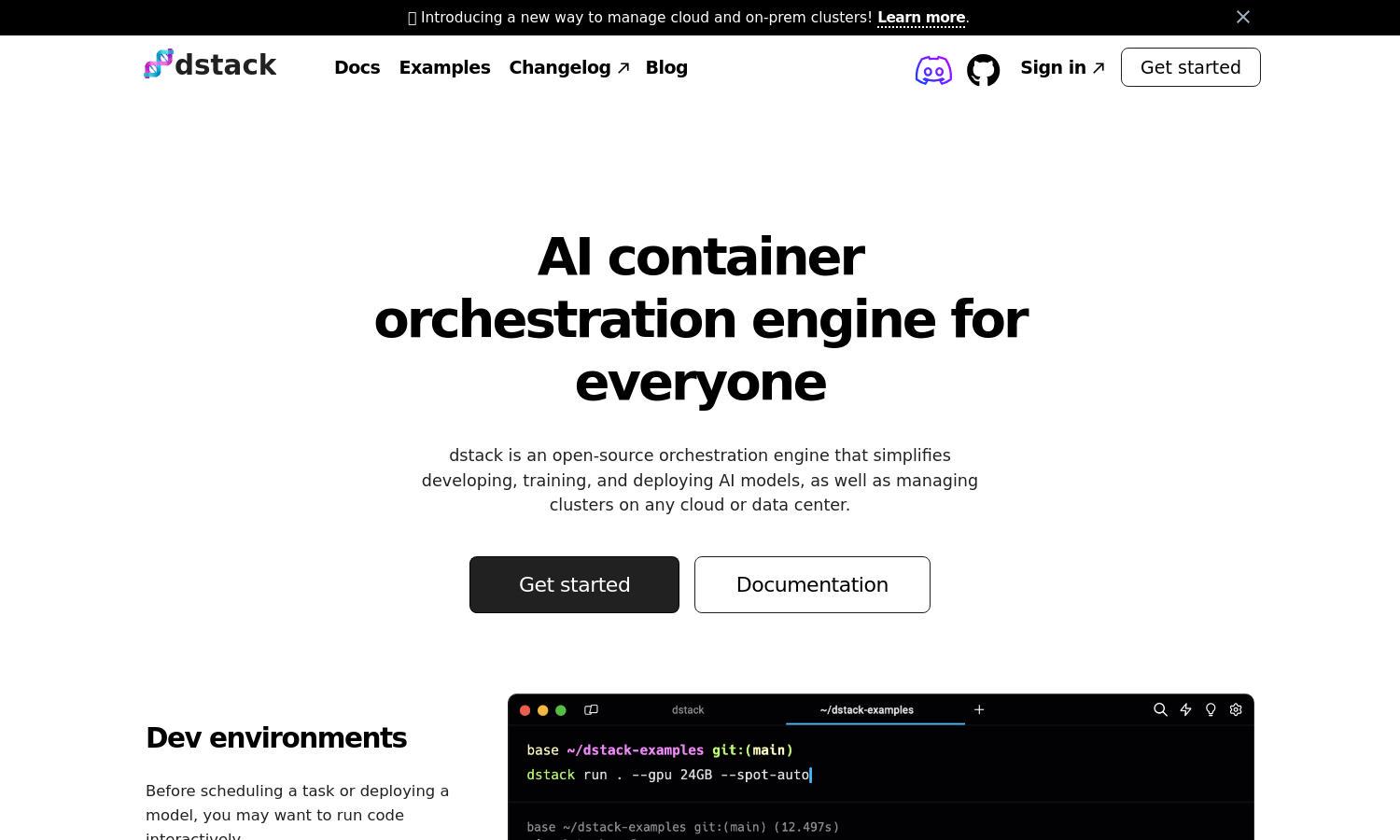
dstack is an innovative open-source AI container orchestration engine that simplifies the deployment of AI applications. Tailored for machine learning engineers, it allows users to effortlessly manage resources, configure environments, and access diverse cloud GPUs, solving the complexity of infrastructure management while enhancing productivity.
dstack offers a free, self-hosted open-source option. With options to connect to AWS, Azure, GCP, and on-prem servers, the platform ensures flexibility for users. Upgrading provides enhanced features for enterprises, allowing better management of AI workloads and resources across multiple cloud environments.
The user interface of dstack is designed for ease of navigation, delivering a seamless experience for AI engineers. Its intuitive layout features straightforward access to dev environments, tasks, and services, ensuring that users can efficiently manage their AI projects without any steep learning curve.
How dstack works
Users interact with dstack by first setting up an account and connecting their cloud or on-premise servers. After onboarding, they can create dev environments and configure tasks through an intuitive interface. By leveraging dstack's robust resource management features, users can easily scale and deploy AI applications across various platforms.
Key Features for dstack
AI-focused Interface
The AI-focused interface of dstack sets it apart as an orchestration engine tailored for machine learning engineers. Users can quickly create and manage AI workloads without needing extensive infrastructure knowledge, streamlining the process of deploying and scaling applications effectively.
Flexible Resource Management
dstack provides flexible resource management that allows users to access multiple cloud GPUs efficiently. This feature enables seamless integration with various cloud providers, ensuring that users can choose cost-effective solutions for their AI workloads while avoiding vendor lock-in.
Auto-scaling Capabilities
dstack's auto-scaling capabilities facilitate effortless load management for web apps and models. This key feature ensures that resources automatically adjust based on demand, optimizing performance and cost-efficiency while providing users with the flexibility needed for dynamic AI applications.
You may also like: