Fallom vs OpenMark AI
Side-by-side comparison to help you choose the right product.
Fallom provides real-time observability for LLMs, enhancing tracking, debugging, and cost management for AI operations.
Last updated: February 28, 2026
OpenMark AI benchmarks over 100 LLMs for your specific tasks, providing instant insights on cost, speed, quality, and stability without setup.
Last updated: March 26, 2026
Visual Comparison
Fallom
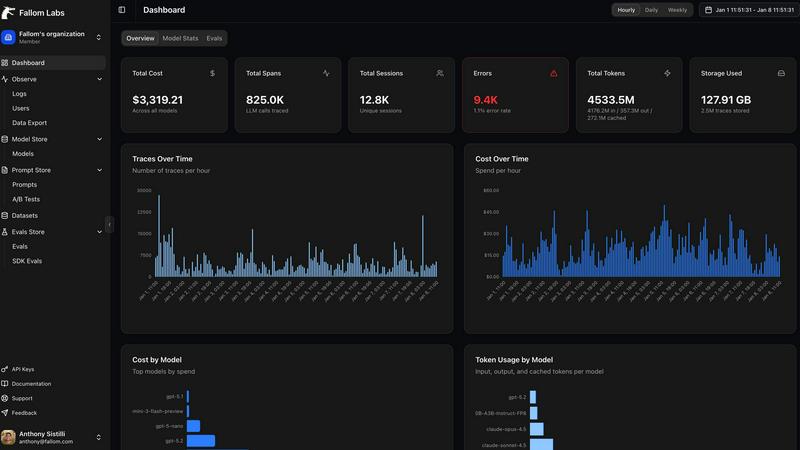
OpenMark AI

Feature Comparison
Fallom
Real-Time Observability
Fallom provides real-time observability for AI agents, allowing users to track every tool call, analyze timing, and debug with confidence. Users can view live traces of LLM interactions, making it easier to identify performance bottlenecks and efficiency issues.
Cost Attribution
With Fallom, organizations can track spending per model, user, and team, providing full cost transparency for budgeting and financial planning. This feature enables accurate chargeback mechanisms, helping organizations manage their AI-related expenditures effectively.
Compliance Ready
Fallom is designed with compliance in mind, offering complete audit trails to support various regulatory requirements, such as the EU AI Act, SOC 2, and GDPR. The platform includes features like input/output logging, model versioning, and user consent tracking to ensure adherence to compliance standards.
Session Tracking
The session tracking feature groups traces by session, user, or customer, providing complete context for every interaction. This capability allows teams to analyze user behavior and assess the impact of changes on specific user groups, enhancing the overall management of LLM operations.
OpenMark AI
Task Benchmarking
OpenMark AI allows users to benchmark various AI models against specific tasks they define. This feature simplifies the evaluation process by enabling users to describe their tasks in simple terms without needing coding skills or technical jargon.
Side-by-Side Comparisons
Utilizing real API calls, OpenMark AI offers side-by-side comparisons of different models. This feature ensures users see genuine performance metrics, allowing for a more accurate assessment of each model's capabilities based on real-time data.
Detailed Performance Metrics
Users can analyze key performance indicators such as cost per request, latency, and scored quality. This feature enables teams to quantify model performance and make data-driven decisions when selecting AI solutions for their projects.
Consistency Tracking
OpenMark AI tracks the stability of model outputs across repeated runs, providing insights into how consistently a model performs over time. This feature is crucial for ensuring reliability and predictability in AI-driven applications.
Use Cases
Fallom
Performance Monitoring
Organizations can use Fallom to monitor the performance of their LLMs in real-time. By analyzing latency and response times, teams can quickly identify and address performance issues before they affect end users.
Cost Management
Fallom enables teams to manage and allocate their AI spending effectively. By tracking costs associated with different models and user interactions, organizations can optimize their budgets and ensure that resources are being used efficiently.
Regulatory Compliance
For companies operating in regulated industries, Fallom provides the tools necessary to maintain compliance with various laws and standards. Its comprehensive audit trails and privacy controls help organizations navigate complex regulatory landscapes with confidence.
Debugging and Optimization
Fallom is essential for developers and data scientists looking to optimize their LLM deployments. With its detailed tracing and session tracking capabilities, teams can pinpoint issues, evaluate model outputs, and make data-driven adjustments to improve performance.
OpenMark AI
Model Selection for Development
OpenMark AI is ideal for development teams looking to select the most suitable AI model for their applications. By benchmarking against specific tasks, teams can identify which models perform best under their unique requirements.
Cost Analysis for AI Implementations
Product managers can use OpenMark AI to conduct thorough cost analyses of different models. This helps them understand the financial implications of using various AI technologies and select options that offer the best balance of performance and cost.
Quality Assurance Testing
Quality assurance teams can leverage OpenMark AI to validate the outputs of chosen models. By running multiple tests and comparing results, they can ensure that the models consistently meet quality standards before deployment.
Research and Development Initiatives
Researchers exploring advanced AI capabilities can utilize OpenMark AI to benchmark emerging models. This enables them to assess new technologies' effectiveness and stability, supporting innovation and informed decision-making in AI research.
Overview
About Fallom
Fallom is an innovative AI-native observability platform tailored for monitoring and optimizing large language model (LLM) and agent workloads. Its design focuses on providing organizations with extensive visibility into every LLM call in real-time, enabling end-to-end tracing that includes essential metrics such as prompts, outputs, tool calls, tokens, latency, and cost associated with each interaction. This level of detail caters to developers, data scientists, and operational teams who need real-time insights to evaluate LLM performance and troubleshoot issues efficiently. With Fallom, enterprises can enhance compliance through features that support session, user, and customer-level context, timing waterfalls for multi-step agents, and comprehensive audit trails. These features include logging, model versioning, and consent tracking. By utilizing a single OpenTelemetry-native SDK, teams can set up monitoring in a matter of minutes, allowing them to live monitor usage, debug issues rapidly, and allocate spending accurately across models, users, and teams.
About OpenMark AI
OpenMark AI is an innovative web application designed specifically for task-level benchmarking of large language models (LLMs). It allows users to articulate their testing requirements in plain language, making the evaluation process accessible to those without extensive technical expertise. By enabling simultaneous testing of prompts across various models, OpenMark AI provides users with comprehensive insights into cost per request, latency, scored quality, and stability across multiple runs. This functionality is essential for developers and product teams who need to select or validate the most appropriate model before integrating AI features into their products. With hosted benchmarking that uses credits, users are relieved from the hassle of managing different API keys for OpenAI, Anthropic, or Google, streamlining the comparison process. OpenMark AI emphasizes real-world performance, showcasing actual API call results rather than relying on potentially misleading marketing metrics. This focus on cost efficiency allows users to make informed choices based on the quality of outputs relative to their expenses, ensuring they select the most effective model for their specific workflows. Free and paid plans are available, with detailed information provided in the in-app billing section.
Frequently Asked Questions
Fallom FAQ
What types of organizations can benefit from Fallom?
Fallom is designed for organizations that utilize large language models, including tech companies, financial institutions, healthcare providers, and any enterprise that relies on AI-driven interactions. Its versatile features cater to developers, data scientists, and operational teams.
How quickly can I set up Fallom?
Setting up Fallom is straightforward and can be accomplished in under five minutes using its OpenTelemetry-native SDK. This quick setup allows teams to start monitoring their LLMs and agents almost immediately.
Is Fallom compliant with data protection regulations?
Yes, Fallom is built with compliance in mind, featuring complete audit trails, logging capabilities, and consent tracking to meet regulatory requirements such as GDPR and the EU AI Act.
Can Fallom integrate with existing tools?
Fallom is designed to work seamlessly with all providers through its OpenTelemetry compatibility. This ensures that organizations can leverage their existing toolsets without being locked into a single vendor.
OpenMark AI FAQ
How does OpenMark AI simplify the benchmarking process?
OpenMark AI simplifies benchmarking by allowing users to describe their tasks in plain language, eliminating the need for complex coding or technical setups. This makes it accessible for users of all skill levels.
What types of models can I benchmark using OpenMark AI?
OpenMark AI supports benchmarking a wide array of models from various providers, including OpenAI, Anthropic, and Google. This extensive catalog allows users to test over 100 models against their specific tasks.
Is OpenMark AI suitable for non-technical users?
Yes, OpenMark AI is designed to be user-friendly, enabling individuals without technical backgrounds to effectively benchmark AI models. The intuitive interface and plain language task descriptions facilitate ease of use.
Can I track performance consistency with OpenMark AI?
Absolutely. OpenMark AI offers features that track the consistency of model outputs across multiple runs, providing insights into how reliably a model performs over time, which is critical for applications requiring stable results.
Alternatives
Fallom Alternatives
Fallom is an AI-native observability platform that specializes in monitoring and optimizing large language model (LLM) and agent workloads. It provides organizations with essential visibility into every LLM call made in production, which is crucial for effective tracking, debugging, and cost management in AI applications. Users often seek alternatives to Fallom for various reasons, including pricing considerations, specific feature requirements, or the need for compatibility with their existing technology stack. When looking for an alternative, it's vital to assess key factors such as real-time observability capabilities, cost attribution features, compliance readiness, and session tracking functionalities to ensure the selected platform meets organizational needs. Choosing a suitable alternative to Fallom involves evaluating the specific requirements of your team and the unique challenges you face in monitoring LLMs. Look for solutions that offer comprehensive observability features, robust cost management tools, and the ability to seamlessly integrate with your current systems. Additionally, ensure the alternative you consider can support compliance with relevant regulations, providing peace of mind while managing AI workloads.
OpenMark AI Alternatives
OpenMark AI is a web-based application designed for benchmarking various large language models (LLMs) based on specific tasks. It allows developers and product teams to evaluate models by comparing metrics such as cost, speed, quality, and stability, making it easier to make informed decisions before deploying AI features. Users often seek alternatives to OpenMark AI for reasons such as pricing variations, specific feature sets, or integration capabilities that better meet their platform needs. When choosing an alternative, it is essential to consider factors such as the range of supported models, the accuracy and reliability of benchmarking results, ease of use, and any associated costs. Look for solutions that provide comprehensive insights into model performance and cost efficiency, ensuring they align with your development goals and workflow requirements.