Agenta
Agenta is an open-source LLMOps platform that centralizes collaboration, evaluation, and observability for reliable AI.
Visit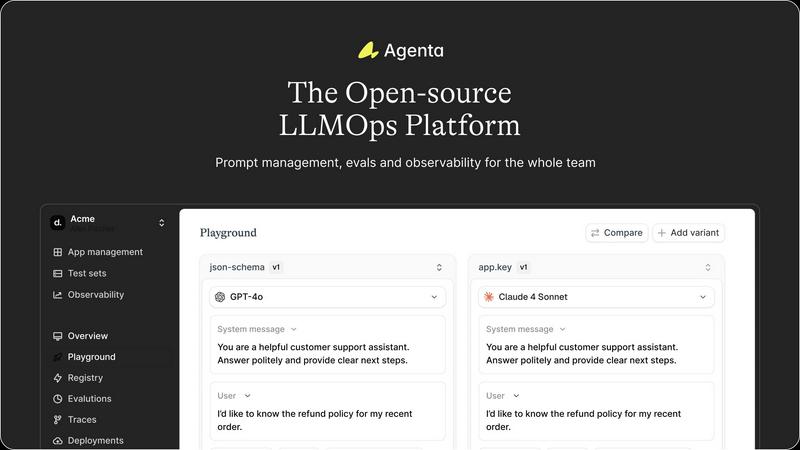
About Agenta
Agenta is an open-source LLMOps platform designed to address the core challenges faced by AI teams in building and deploying reliable large language model (LLM) applications. This platform serves as a centralized hub that fosters collaboration among developers, product managers, and subject matter experts, transitioning from chaotic and siloed workflows to structured, evidence-based processes. Agenta mitigates the unpredictable nature of LLMs by offering integrated tools throughout the entire development lifecycle. Teams can experiment with various prompts and models in a unified playground, run systematic evaluations—both automated and human—to validate changes, and monitor production systems with detailed tracing to quickly identify and debug issues. By providing a single source of truth and replacing guesswork with structured workflows, Agenta enables teams to iterate faster, deploy with confidence, and maintain the performance of their applications over time. Being model-agnostic and open-source, Agenta ensures flexibility and avoids vendor lock-in, making it a practical foundation for teams serious about operationalizing their LLM applications.
Features of Agenta
Centralized Workflow Management
Agenta centralizes all aspects of LLM development, including prompt management, evaluations, and system traces, into one platform. This eliminates the chaos of scattered tools and enables teams to maintain a cohesive workflow.
Unified Playground
With Agenta’s unified playground, teams can experiment with different prompts and models side-by-side. This feature allows for easy comparisons and iterative development, facilitating faster and more informed decision-making.
Automated Evaluation System
The platform includes an automated evaluation system that enables teams to systematically run experiments and track results. This evidence-based approach replaces guesswork with data-driven insights, ensuring that every change is validated before deployment.
Integrated Observability Tools
Agenta provides integrated observability tools that allow teams to trace every request and identify failure points quickly. Annotating traces and turning them into tests streamlines debugging and enhances overall system reliability.
Use Cases of Agenta
Collaborative Prompt Development
Agenta is ideal for teams looking to enhance their prompt engineering process. With its centralized platform, developers, product managers, and domain experts can collaborate seamlessly, leading to better prompt designs and improved model performance.
Systematic Experimentation
Teams can use Agenta to conduct systematic experimentation, comparing various prompts and model outputs. This capability allows for rapid iterations and more effective testing, ultimately improving the quality of LLM applications.
Performance Monitoring
Agenta’s observability features enable teams to monitor the performance of their LLM applications in real-time. By tracing requests and identifying regressions, teams can ensure their systems remain reliable and effective.
Evidence-Based Decision Making
The platform empowers teams to make informed decisions based on systematic evaluations and feedback from domain experts. This evidence-based approach reduces the risk associated with deploying LLM applications and enhances overall team confidence.
Frequently Asked Questions
What is LLMOps?
LLMOps refers to the operational practices and tools designed to manage the lifecycle of large language models. It encompasses prompt management, experimentation, evaluation, and deployment to ensure reliable application performance.
How does Agenta improve collaboration among team members?
Agenta fosters collaboration by centralizing workflows and providing a platform where product managers, developers, and subject matter experts can work together. This reduces silos and enhances communication, making it easier to share insights and feedback.
Can Agenta integrate with existing tools and frameworks?
Yes, Agenta is designed to be model-agnostic and integrates seamlessly with various frameworks and tools, including LangChain, LlamaIndex, and OpenAI. This flexibility allows teams to leverage their existing tech stacks without vendor lock-in.
Is Agenta really open-source?
Absolutely! Agenta is an open-source platform, allowing anyone to dive into the code, contribute to its development, and customize it according to their specific needs. This openness fosters a community of developers and encourages collaborative improvement.
Explore more in this category:
Similar to Agenta
Ornold MCP lets AI agents control Chromium and antidetect browsers: click, type, read screens, record workflows, replay profiles without scripts.
AIQualityHQ instantly checks your AI prompts for structure, safety, privacy, and accuracy with deterministic scores in under 10ms.
RedLinz turns screenshots into AI prompts by letting you circle and annotate exactly what you want an LLM to change.
Locai lets you run powerful AI models on your own hardware, keeping data private and cutting cloud costs.
Clearcote is an open-source, de-Googled Chromium drop-in for Playwright and Puppeteer that gives you engine-level fingerprint control for a single.
HypeShare lets you send large files up to 10GB securely with end-to-end encryption and no signup required.
Stop guessing where to launch and get your SaaS in front of buyers across curated directories instantly.